Help! Timeouts!
 Ian
~ October 30, 2018
Ian
~ October 30, 2018
A lot of the customer support queries we get at MemCachier are about client timeouts. It’s unusual for these to be due to problems with our infrastructure – we have a sensitive monitoring system that alerts us quickly when there are problems with the machines we use to host MemCachier caches. The timeouts that clients see are most often the result of transient network glitches and problems with client libraries. In this article, we’re going to try to explain a little of what’s going on.
LAN vs. Cloud
Let’s start by comparing two caching scenarios, both with an
application server running the code of your web application, and a
cache server running a cache system like memcached:
LAN The “classic” self-hosted setup: you own the physical machine running your application and run your own
memcachedserver on another machine on the same local network.Cloud What most of us do nowadays: your application runs on a virtual machine in the cloud, and you use a cloud service (like MemCachier) for caching instead of running your own
memcachedserver.
What does the network between application server and cache server look like in these two scenarios?
In the first case, the application server and the cache server are on the same LAN and there are a limited and known number of network devices between the two machines – maybe just an Ethernet hub, maybe a single router. In this case, the network performance between the two machines should be fast and predictable (assuming no-one unplugs something!). In the cloud setting, you just don’t know what networking cleverness is going on between the virtual machines you’re using: AWS uses software defined networking to implement their Virtual Private Cloud system, and customers don’t know enough about what’s there to predict performance.
We can get a quantitative idea of how this behaves by looking at ping times. The first plot here shows a histogram of ping times between my desktop machine and the laser printer sitting right next to it. The two devices are on the same subnet and are connected through a Netgear Ethernet hub.
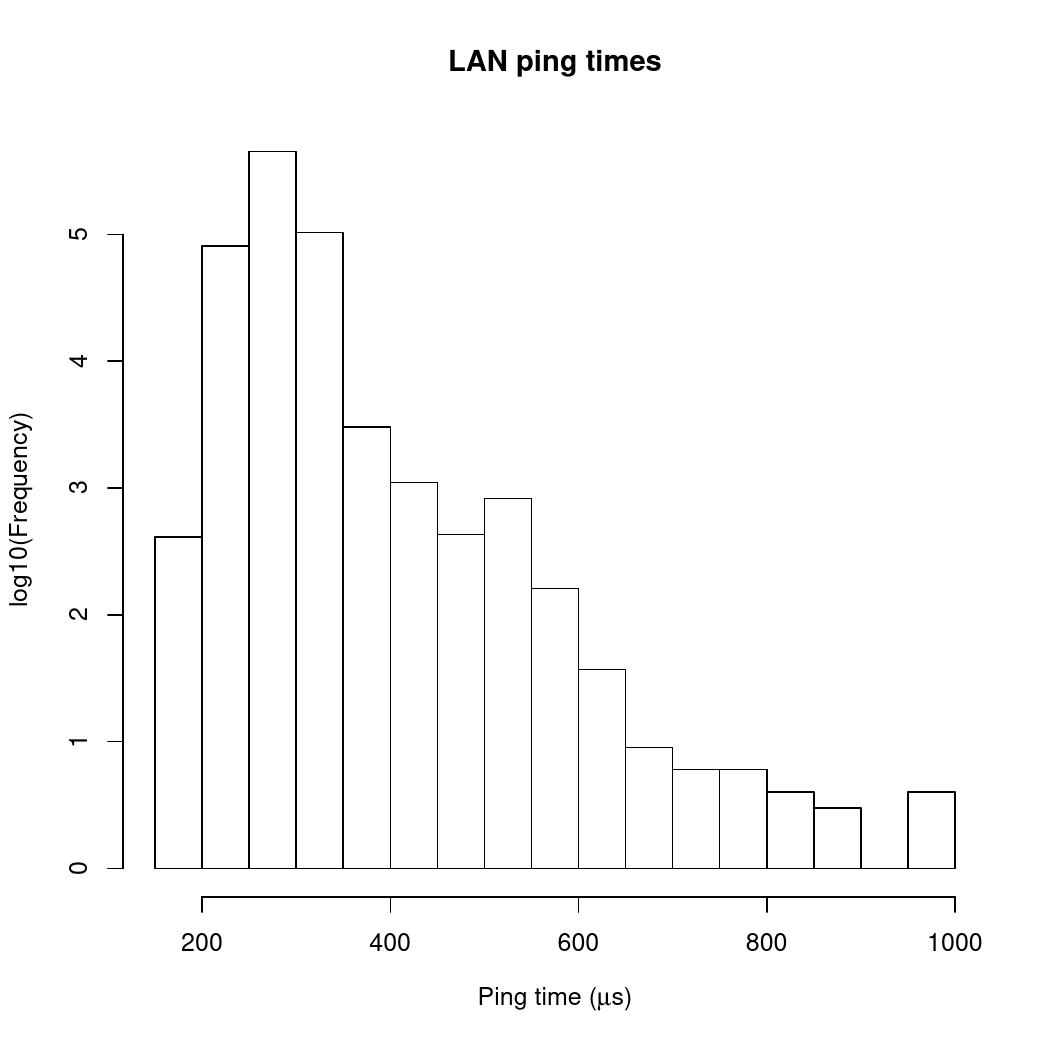
The data to make this plot was collected by doing 10 ICMP pings per second between my desktop machine and the printer for most of a day. The x-axis shows ping time in microseconds and the y-axis shows how often each range of ping times was seen (on a log axis to make rarer events more visible).
There are two things to notice here: first, the ping times are short (all less than about 1000μs); second, there are no real outliers.
What about on AWS? The next plot shows results from the same experiment for two AWS EC2 t2.micro instances running on the same subnet within the same availability zone.
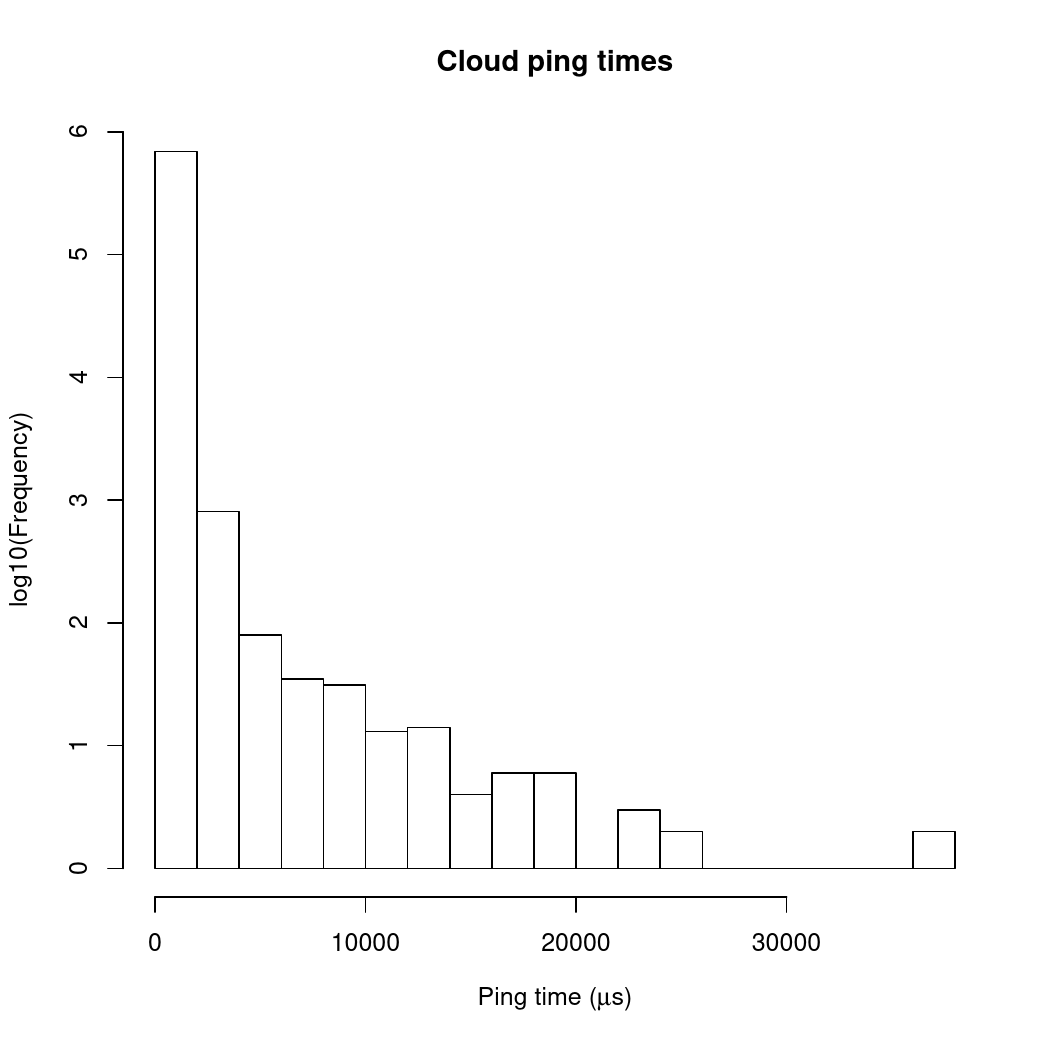
Again, there are two things to notice, which are kind of the exact opposite of the situation for the LAN data: first, the ping times are longer, mostly in the 10-20,000μs range (i.e. 10-20 times longer than in the LAN case); second, there is at least one naughty outlier that took something like 35,000μs.
Two factors may be contributing to the differences between the LAN and cloud results. First, there is more (and more complex) network hardware between the two cloud instances than between my desktop machine and my printer. That can lead both to longer transit times for network packets (more routers to go through) and larger variability in packet transit times (your ping packet could be queued in a router behind a burst of packets from other machines on the same segment, or in the worst case, a router queue overflows and your packet gets dropped and needs to be resent somewhere along the way). The second factor, which in this case probably contributes more to variability than to the median transit time, is that the machine instances we’re using aren’t whole physical machines: they’re virtual slices of large machines, with other customers’ applications running in other slices of the physical hardware. If you’re unlucky, your application can end up sharing physical hardware with a “noisy neighbour” with high or bursty network demand. The hypervisors used to isolate virtual instances on the same physical hardware are good at evening out network bandwidth demand between instances, but they’re not perfect.
What does this all mean for timeouts? That 35ms outlier on the EC2 ping time plot was derived from just a day’s worth of data. Run the same experiment for longer, and you’ll see outliers pushing out further and further. It’s pretty much impossible to set a limit to the round trip times you might see on a cloud network. The network performance on AWS, for example, is usually really good, but sometimes you can see long round trips, way out of line with what you would expect on a simpler network. If you wait long enough, you’re more or less guaranteed to see a round trip longer than any reasonable timeout you might set up. The key thing is that round trip times have a probability distribution with a long tail, so it’s not possible to 100% rule out any particular value – picking a longer timeout will make it less probable that you see a timeout, but it will never reduce the probability to zero.
Timeouts are a fact of life in distributed systems. You have to learn to live with them. There are two aspect to living with timeouts. First, whatever client library you use must be able to deal with them when they do happen. Second, you want to configure your client library’s timeout settings to reduce the frequency of false alarms, without making it too hard to detect real problems. Let’s deal with that second point first.
So timeouts are a fact of life. What do we do?
The idea of having a timeout in a memcached client library is to
detect situations where the memcached server has “gone away”. “Gone
away” can mean that the server has crashed (due to a hardware fault, a
power failure or some other reason) or that there has been a break in
network connectivity between client and server (someone could have
unplugged something they shouldn’t have unplugged in the data center,
there could be a hardware problem on one of the routers between client
and server, there could be a transient loss of connectivity due to
network reconfigurations, and so on).
Since the cache layer is supposed to be fast, because we want to use
it to speed up our applications, we want to get to hear about problems
quickly! So we should set up short timeouts in our client libraries,
right? Dalli, the popular memcached client library for
Rails, recommends the following values for some of its timeout
parameters (all in seconds):
- Time to wait before trying to recontact a failed server:
:down_retry_delay => 1 - Connect/read/write timeout for socket operations:
:socket_timeout => 0.5 - Time to sleep between retries when a failure occurs:
:socket_failure_delay => 0.01
These settings are completely reasonable in a LAN setting. If you’re using a cloud-based service like MemCachier, these parameter settings are not so good. Remember how those ping times between EC2 instances were 10-20 times longer than between directly connected machines? If you use these settings, you’re going to see a lot of timeouts!
Here’s what we recommend for Dalli configuration if you’re using MemCachier:
:down_retry_delay => 60,:socket_timeout => 1.5,:socket_failure_delay => 0.2
These settings are a trade-off between triggering too many timeouts
and detecting when there’s a genuine problem. That’s more appropriate
for a cloud setting, where you will sometimes see longer round trip
times to your cache server just because of network variability.
Setting the timeouts longer like this reduces the number of “false
alarm” timeouts that you see. However, it doesn’t eliminate them
completely, so your memcached client library needs to know what to
do if a timeout does occur!
When your client library does bad things…
When a timeout does occur, or some network error causes a connection
to be dropped, you want your client library to retry and reconnect
seamlessly. Ideally, the only impact on your application should be at
worst a single cache miss and the corresponding extra database query
or page fragment render. Most client libraries do this right: Dalli
works well, the Python memcached client libraries that we know about
are all good, the PHP libraries we know about are too. However, there
is one client library that has real problems with timeouts and
reconnections, and is the source of most of the timeout-releated
customer support tickets that we see. That’s the spymemcached Java
library.
We’ve looked into this in some detail, but haven’t been able to identify exactly what the fault with this library is or how to correct the reconnection behaviour, but we’ve had multiple clients report problems arising from this library. It seems that even a single timeout is enough to trigger a series of cascading errors that seriously affects application performance.
Fortunately, there is another Java memcached library that seems to
work correctly with MemCachier. That’s XMemcached, which is what we
now recommend that customers with Java applications
use to connect to MemCachier.
Conclusions
Pretty simple really:
- If you use a cloud service for caching (or anything else), you will see timeouts. You can reduce their frequency, but you can’t eliminate them entirely.
- You need to use a client library that can handle timeouts correctly when they do occur. Most client libraries do a good job, but there are exceptions.
- You should configure the timeout settings for your client library to reduce the frequency of timeouts. Using the same timeout parameters in a cloud setting as for servers connected on a LAN is asking for trouble.