How much Memcache do you need?
 Sascha
~ August 27, 2018
Sascha
~ August 27, 2018
Caching is a technique used in a wide range of contexts to increase the performance of storage systems. For example, modern microprocessors all have fast cache memory built into them, so that repeated accesses to the same memory addresses come from the fast cache storage, rather than from the slower main memory. In a similar way, operating systems maintain a cache of disk buffers in main memory, so that repeated reads from the same disk blocks come from the cached data rather than needing to be read from disk, which is much slower than memory.
The same kinds of considerations apply to caching for web and mobile applications with Memcache. In this case, it’s common to cache the results of database queries, partial page renders, or the results of other application-specific computations.
In any caching application, there are two questions that have to be answered. First, “What should I cache?” and second, “How big a cache do I need?”.
In many cases, the answer to the first question is determined by the web framework you use. For example, Django, Laravel, Spring Boot and others all have integrated caching systems that simplify the caching of database query results and HTML page renders. These frameworks usually also expose a lower-level API for doing application-specific custom caching.
However, the second question is trickier. At MemCachier, we get questions about cache sizing from customers all the time. Fortunately, there is a simple and systematic way to go about choosing a cache size, which we’re going to describe in this article.
A simple experiment
Caching works because most applications do not access data in a completely uniform way. Some data is used often, while other data items are accessed only very infrequently. Think about a microblogging site like Twitter as an example: HTML renders of posts from users with lots of followers will be used very frequently, since they need to appear in the timelines of all of the user’s followers. Posts by users with few followers need to be rendered less often. In this situation, it makes sense to pre-render and cache recent posts from the users with most followers, so as to avoid repeating the work of rendering the posts every time they need to be displayed.
So how do we decide how big a cache to use in a setting like this? The goal is to have a cache that’s big enough to fit all the data that is accessed frequently, but that’s not too much bigger. A cache that’s too big would be a waste of resources (which generally translates to money!) and a smaller cache will yield poor performance, because frequently used data will get evicted by other frequently used data (the word “thrashing” is sometimes used to describe this behaviour, where cached items are repeatedly evicted then recalculated and recached). This ideal cache size corresponds to what’s usually called your application’s working set. There is a simple experiment to determine the size of the working set.
For this experiment, you start with a small cache and wait until your application fills it with data. You then measure the hit rate, i.e., the percentage of get requests that access a value that’s already in the cache (for MemCachier caches, the hit rate is reported on your cache’s analytics dashboard). If the hit rate is high enough (above about 80%), there is no need to continue the experiment as your cache is probably large enough. Suppose though that you see a hit rate of only around 10%. This means that 90% of requests are not finding a value in the cache, so 90% of cache accesses lead to a recomputation of the data item (a database query, a page render, or whatever it is). We thus continue the experiment by increasing the cache size and waiting until it fills up again. Once full we again measure the hit rate, which should now be higher.
Note: Filling up a cache should not take very long. If it does, you either need to cache more aggressively or you have already reached the best caching performance (hit rate) you are likely to get in your application.
Continue this experiment by gradually increasing the cache size and measuring the hit rate once the cache fills up. The result of this type of experiment will probably look something like this:
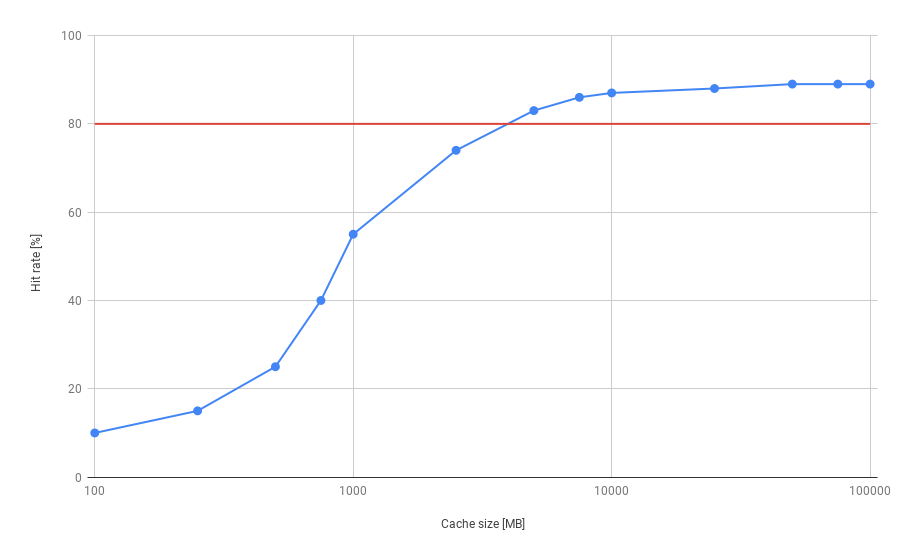
The hit rate increases until it reaches a point of diminishing returns, i.e., increasing the cache size further doesn’t increase the hit rate significantly. In the figure above this happens after the cache size reaches 5GB where the hit rate is above 80%. As you can see, increasing the cache size beyond this point has little influence on the hit rate. This indicates that in this case a 5GB cache can contain the whole working set.
Why 80%?
We’ve mentioned a couple of times that aiming at a hit rate of 80% is desirable. The reason for this is that a lot of processes in nature are approximately distributed according to Pareto or power law distributions. The specifics of these distributions aren’t so important in this context, but it’s useful to know about the “80-20 property” that these distributions have. It states that if data accesses follow a Pareto distribution, then 20% of the data will be accessed 80% of the time. The job of a cache is to hold this 20% of the data. (The 80-20 rule is obviously an approximation, but it’s a useful rule of thumb.)
In real life, your case might differ. Your data access patterns might be more predictable, allowing you to get hit rates closer to 100%. That’s great! You might also have more uniform data access patterns, meaning that your hit rate never exceeds 60%. In either case though, the experiment we describe here will allow you to ensure that your hit rate is low because of the characteristics of your data access patterns and not because your cache is too small.
Basically: always perform this experiment and aim at an 80% hit rate.
Performing the experiment
While the description of the experiment is simple, the implementation can be messy. If you run your own Memcached server, you will need to restart your server each time you configure it for a new size, which will result in the loss of the entire cache (and you will then need to wait for your application to refill the cache). You could run your own Memcached cluster, but this requires launching multiple servers and restarting your application so it picks up the new servers each time you change the cluster setup. Each time you add a machine to your cluster, you will lose a portion of the data in your cache, because part of the key space will be associated with the new server and will be lost from the machines where it was formerly stored.
With MemCachier this experiment becomes effortless. You can scale your cache up or down seamlessly without losing any data. In addition, your cache’s analytics dashboard shows you exactly the right information for this experiment, i.e. the hit rate and the cache usage.
If you have any questions about cache sizing (or anything else cache-related!), you can always ask MemCachier’s engineers for help.