MagLev, our new consistent hashing scheme
 Sascha
~ September 1, 2017
Sascha
~ September 1, 2017
A key feature that MemCachier offers its clients is the ability to use multiple proxy servers to access their cache. This is important because most issues that clients experience are related to network delays or general connectivity. In such cases a memcached client can fall back to a different proxy and still have access to the entire cache.
To implement this feature MemCachier uses consistent hashing. Just like regular hashing, this assigns every key to a specific back-end, but it has a crucial advantage: if the number of back-ends changes, only very few keys need to be reassigned. For example, if the number of back-ends increases from 3 to 4, a naive hashing scheme would assign 75% of the keys to a different back-end after the change. In such a case, a good consistent hashing scheme only changes the assignments of 25% of the keys.
What’s wrong with our current scheme?
Until now we have used the most basic consistent hashing scheme, which is based on a ring. Each back-end is assigned a point on the ring (based on the hash of an ID used to identify the back-ends) and is in charge of all values on the ring up to the point that belongs to the next back-end. As an example, consider a ring with 100 points and 3 back-ends. The ID of each back-end will be hashed to a point on the ring, i.e. a point in the interval [1, 100] identifying all the points in the ring. Ideally we’d like for the back-ends to be equally spaced around the ring, e.g., at 33, 66, and 99, which would assign all keys that map to points on the ring between 33 and 65 to the back-end at 33, and so on. However, the size of the segment of the ring each back-end is responsible for can vary quite a lot, which results in skew, e.g., if the 3 back-end IDs hashed to 12, 17, and 51, the assignment of keys to back-ends would be quite uneven.
When simulating an example architecture with 9 back-ends and a realistically sized ring (2^64 points) over 100 rounds, each time ordering the backends by their share of the ring, the distribution of the percentage of the ring each back-end gets looks like this:
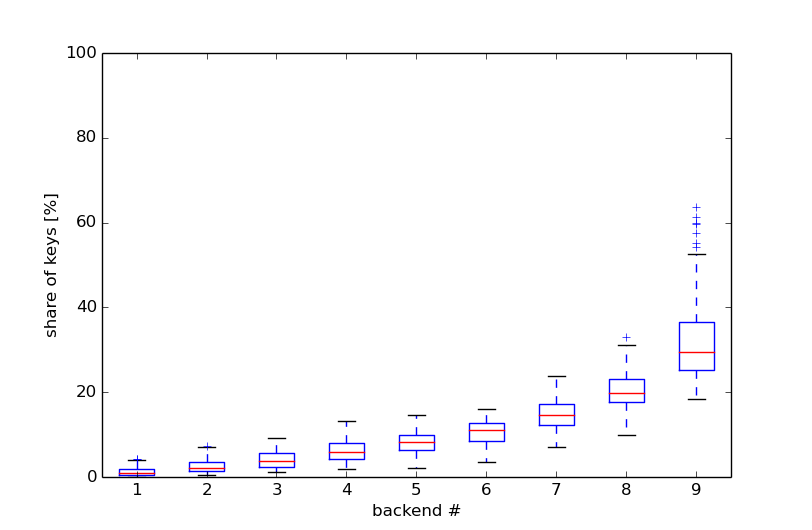
While the one back-end gets around 30% of all keys, others are assigned hardly any keys. This effect is generally dampened by assigning each back-end to multiple points on the ring in order to statistically even out the skew. For 100 points per back-end the situation looks like this:
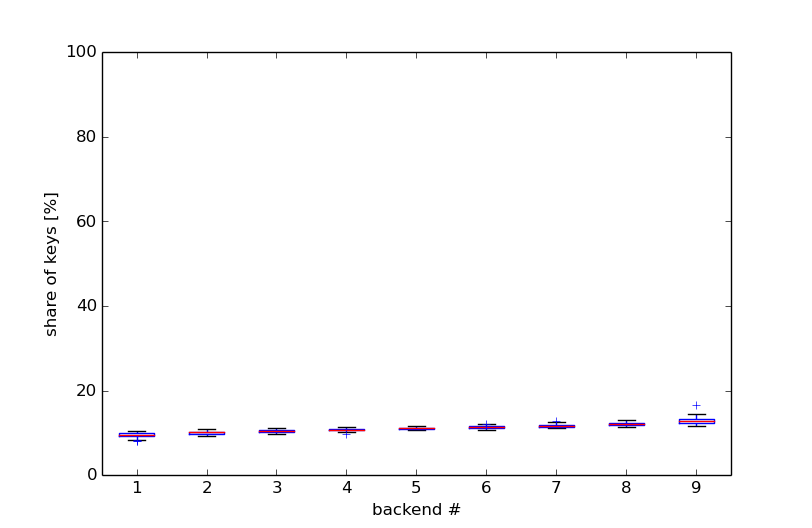
This looks much better, but if we zoom in and look at the skew in more detail, we see how bad it still is:
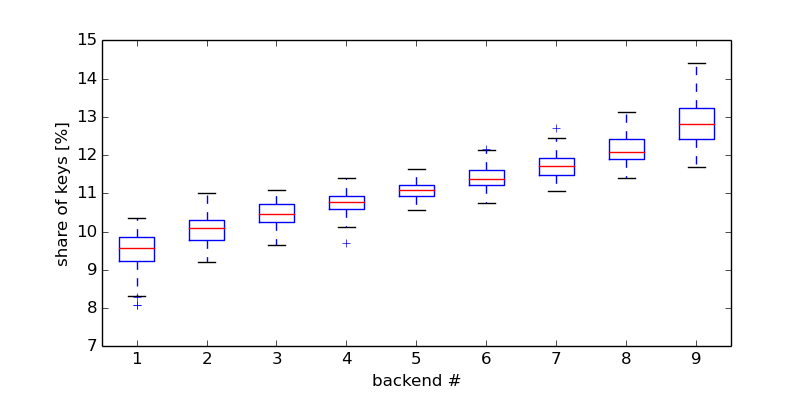
We can see that the median (the red center line in the boxes) of the most loaded backend is 30% above the least loaded backend. It is not unlikely (within the 95 percentile interval, the whiskers around the boxes) for the most loaded back-end to get 14.4% of the keys while the least loaded one only gets 8.3%. This is nearly a factor of two skew between the most and least loaded back-end!
Enter MagLev
MagLev is a consistent hashing algorithm developed at Google and published in 2016. Its main advantage is that it has no skew at all. It achieves this with a deterministic algorithm that builds a lookup table for keys in a round robin fashion, guaranteeing that each back-end will get the same amount of keys. What about the remapping of keys when a back-end changes? In theory, it is basically the same as the ring based consistent hashing, that is 1/(# of back-ends) or 25% when going from 3 to 4 back-ends as in the example above. In practice it is more predictable as there is hardly any variability around the 1/(# of back-ends) compared to the ring based scheme. The only downside of MagLev is that the calculation of the assignment lookup table is resource intensive and thus takes time. However, since back-ends hardly ever change in our clusters this is not an issue.
For the interested reader the paper can be found here.
What changes for our customers?
The most noticeable change is a reduction in early evictions. In a sharded cache, skew in the distribution of keys can result in evictions before the global memory limit is reached. We counteract this by assigning more memory to a cache than its advertised limit but evictions still start before 100% of the cache is used.
As we switch over from simple consistent hashing to MagLev, there will be a short transition period with a slight performance hit when getting values from the cache. The reason is that changing the consistent hashing scheme will change many assignments of keys to back-ends. Since this would result in a lot of lost values, we will have a transition phase where we fall back to the ring based consistent hashing whenever a key is not found. This will result in a latency increase for get misses as shown by the red line (average of the red dots) after the switch to MagLev (black dotted line):
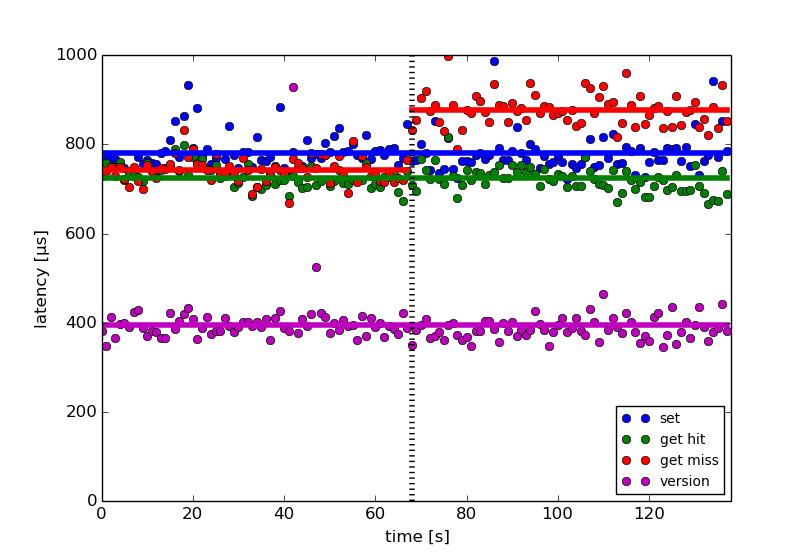
The expected latency increase for get misses is between 100µs and 200µs, which is 5-10% of the total request time generally seen by clients. During this transition period (which will last 30 days), cache statistics displayed in the MemCachier dashboard will also be misleading, because every get miss will be counted twice.